
Authors

The document parsing space has a transparency problem. Companies claim impressive accuracy numbers, but comparing systems fairly is nearly impossible. Benchmark datasets are often clean, academic collections that don't reflect production complexity. Evaluation metrics from the OCR era systematically misclassify rich generative outputs as errors. And when companies do share results, the underlying data and methodology remain opaque.
We're changing that.
Today, we're open-sourcing SCORE-Bench—a diverse dataset of real-world documents with expert annotations, complete with benchmark results from leading document parsing systems. The full dataset with data description and evaluation results are available now on Hugging Face, while the evaluation code is shared on GitHub.
Why Another Benchmark?
Fair question. Existing benchmarks tend to showcase clean PDFs that rarely represent what organizations actually process: scanned invoices with skewed text, financial reports with deeply nested tables, forms filled out by hand, technical manuals with complex multi-column layouts, and so on.
SCORE-Bench includes documents that differentiate production-ready systems from research prototypes:
- Complex tables: Nested structures, merged cells, irregular layouts
- Diverse formats: Scanned documents, forms, reports, technical documentation
- Real-world challenges: Handwriting, poor scan quality, mixed languages, dense layouts
- Multiple domains: Healthcare, finance, legal, public sector, and more
Every document has been manually annotated by domain experts not algorithmically generated from metadata. This ensures evaluation reflects actual extraction quality, not artifacts of automated labeling.
The Evaluation Problem with Generative Parsing
Traditional metrics like Character Error Rate (CER) or Tree Edit Distance (TEDS) were designed for deterministic OCR systems. They assume one correct output exists. But modern vision-language models are fundamentally different.
Generative systems naturally produce diverse valid representations of the same content. One might extract tables as plain text, another as structured HTML, a third as JSON with explicit relationships. All three could be semantically equivalent yet traditional metrics would heavily penalize the structured formats despite them often being more valuable for downstream applications.
This creates systematic measurement bias. Systems that provide rich semantic structure for RAG, search, or analysis get punished by metrics designed for surface-level string matching. The more sophisticated a system becomes at understanding document semantics and providing contextually appropriate representations, the more legacy evaluation frameworks penalize it. This paradox has made it nearly impossible to fairly compare modern document parsing approaches.
SCORE: Evaluation for the Generative Era
We developed SCORE (Structural and Content Robust Evaluation) specifically to address this gap. SCORE is an interpretation-agnostic framework that separates legitimate representational diversity from actual extraction errors. You can read more about our evaluation framework in this blog post.
We've already open-sourced the complete evaluation framework with detailed documentation on calculating SCORE metrics. We've shared labeled examples showing ground truth formats. Now, with SCORE-Bench, we're releasing a public dataset so the community can:
- Benchmark their own systems using the same data and methodology we use internally
- Reproduce our results and validate our claims independently
- Compare approaches fairly across different architectural paradigms
- Track progress as document parsing technology evolves
Provide your own labeled ground truth and use the framework to generate comprehensive metrics across content fidelity, hallucination control, coverage, structural understanding, and table extraction.
Measuring the Landscape
We evaluated leading document parsing systems on SCORE-Bench in addition to our previously published benchmarking results on internal dataset. The results highlight that while some systems specialize in specific niches, Unstructured delivers the most robust performance across structure, content, and table accuracy.
Content Fidelity: The Accuracy of Text
Standard text matching often fails when layout changes. We use Adjusted CCT (Clean Concatenated Text), which uses word-weighted fuzzy alignment to measure semantic equivalence despite structural variation.
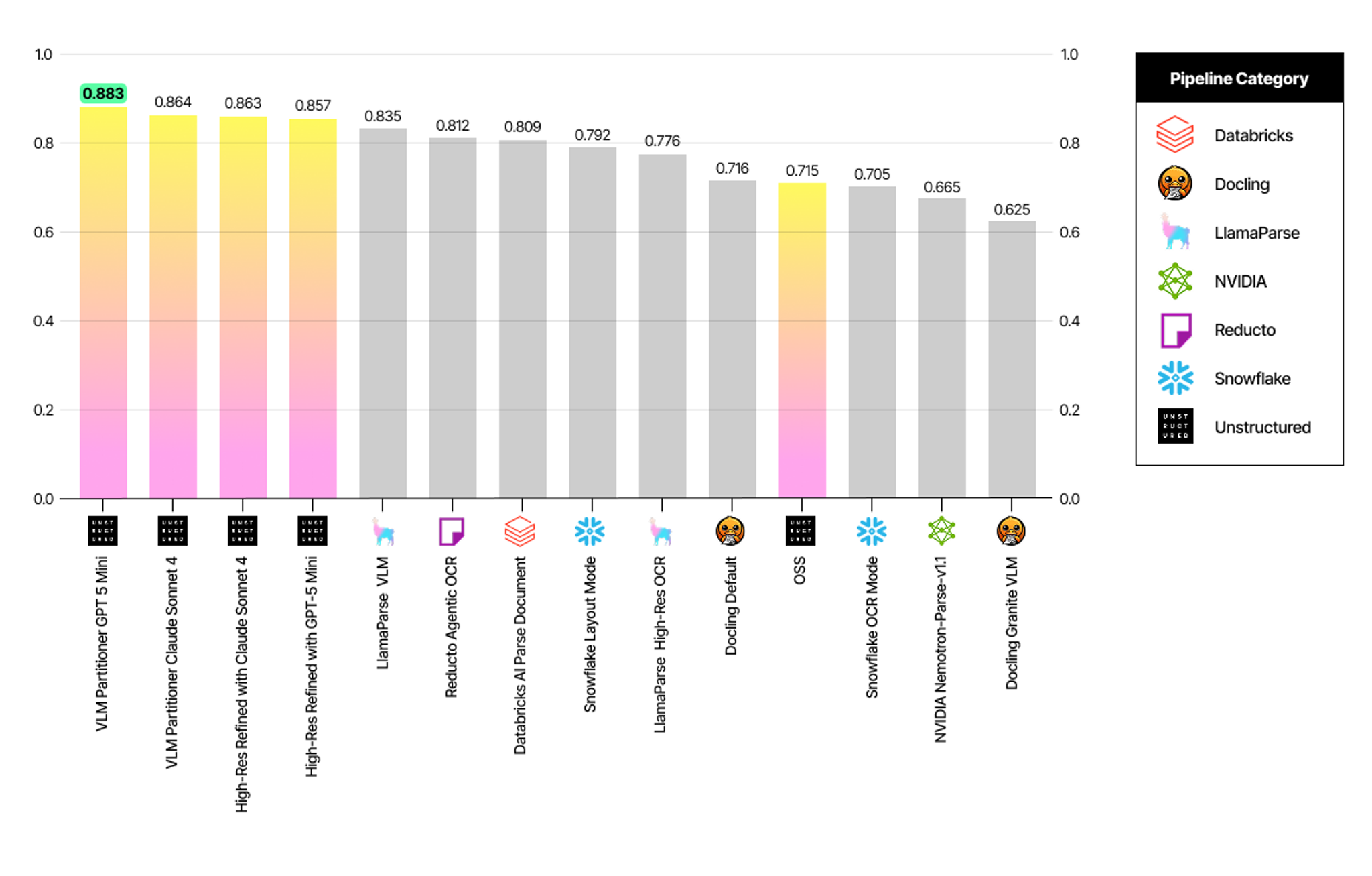
The Unstructured VLM Partitioner GPT-5-mini pipeline leads in Content Fidelity with an Adjusted CCT of 0.883. In fact, the top four performing pipelines are all variants of Unstructured pipelines. This indicates that the Unstructured pipelines capture the actual text content more accurately than other tools, even when that text is buried in complex layouts.
The Hallucination vs. Recall Trade-off
Generative parsing requires a balance between finding all the text (Percent Tokens Found) and inventing text that isn't there (Percent Tokens Added).
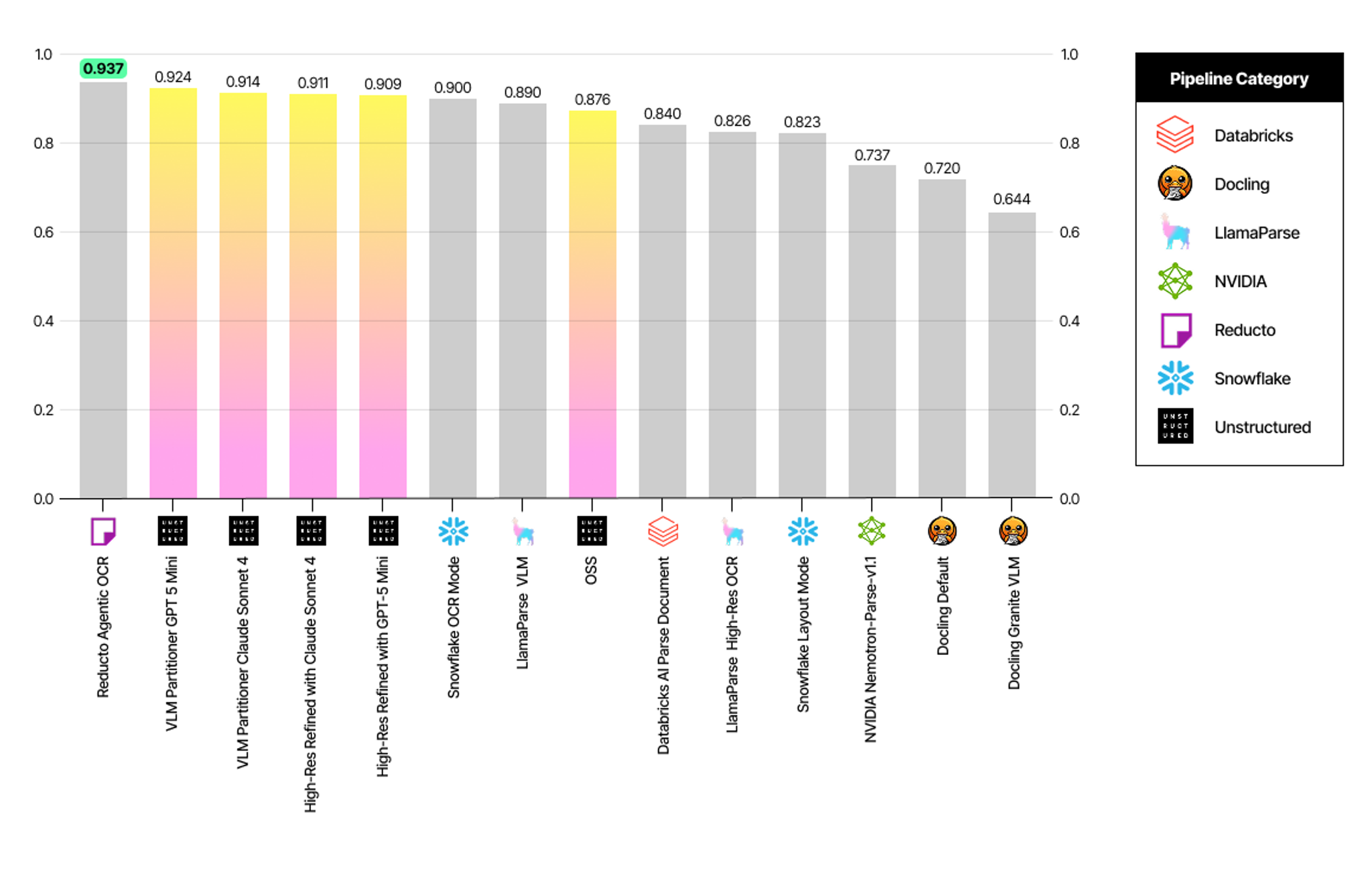
Percent Tokens Found metric measures the proportion of reference tokens preserved.
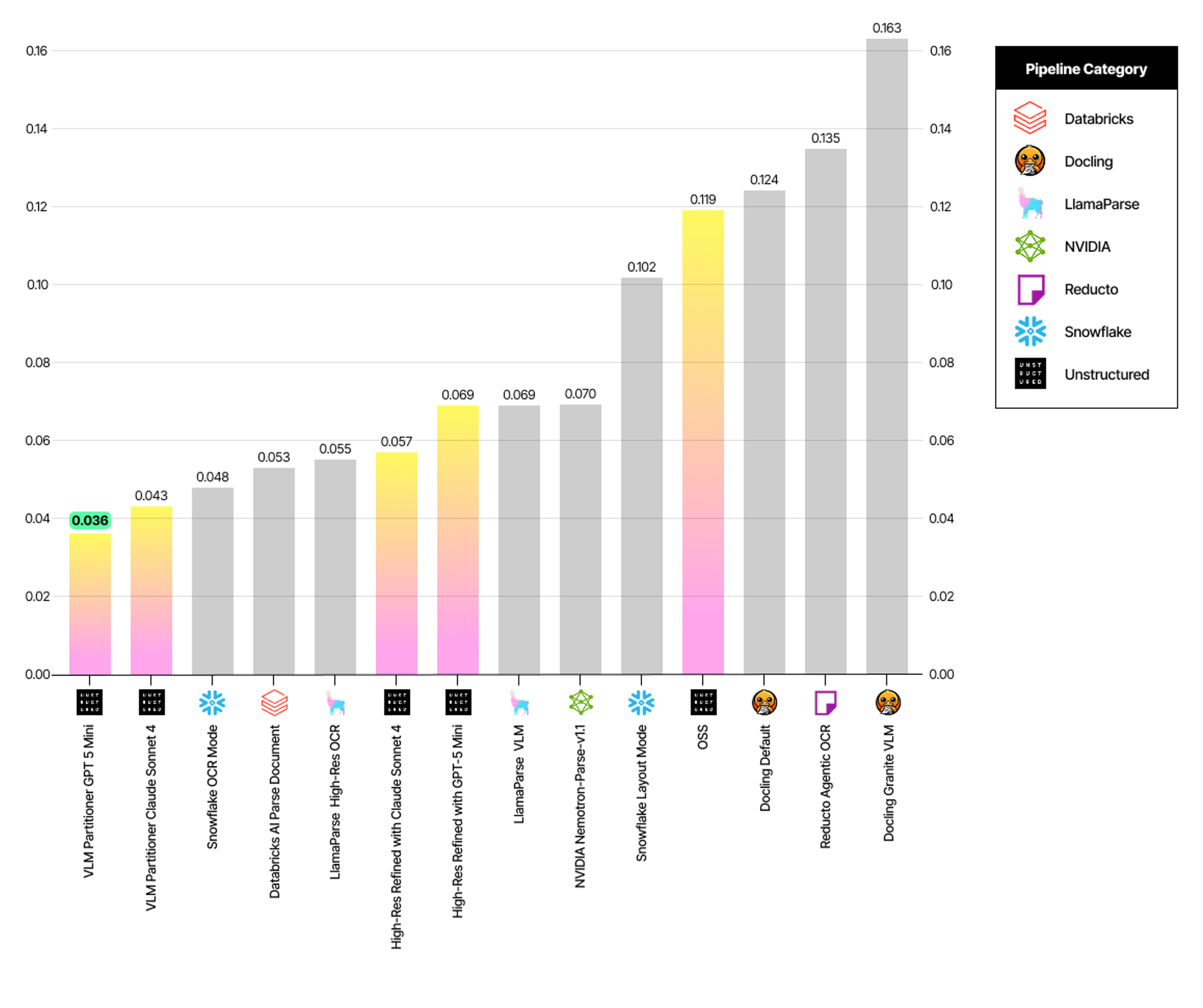
Percent Tokens Added measures the proportion of spurious tokens generated.
Insights:
- Unstructured pipelines are the leader in hallucination control (
Percent Tokens Added). The Unstructured VLM Partitioner GPT-5-mini pipeline achieves the lowest score inPercent Tokens Addedat 0.036. This is a significant finding, as it proves that Unstructured's pipelines are the most robust at mitigating the risk of data poisoning via hallucination, making them the most production-ready solution for sensitive downstream applications like RAG. - Reducto’s Agentic pipeline achieves the highest
Percent Tokens Found, however, it comes at a significant cost: it has the third-highest hallucination rate (Percent Tokens Added) among all pipelines at 0.124. This high rate of spurious tokens can hurt downstream performance in RAG just as much as missing context.
Unstructured strikes the critical balance: our pipelines achieve the second-highest Percent Tokens Found (0.924) while maintaining an exceptionally low hallucination rate Percent Tokens Added (0.036). This offers a safe but comprehensive extraction, proving to be the most production-ready solution by mitigating the risk of data poisoning via hallucination.
Table Extraction: The Hardest Problem
Tables are a major challenge. We measure this using Cell Content Accuracy (reading the text inside the cell correctly) and Cell Level Index Accuracy (understanding which row/column that text belongs to) among other metrics.
Cell Content Accuracy
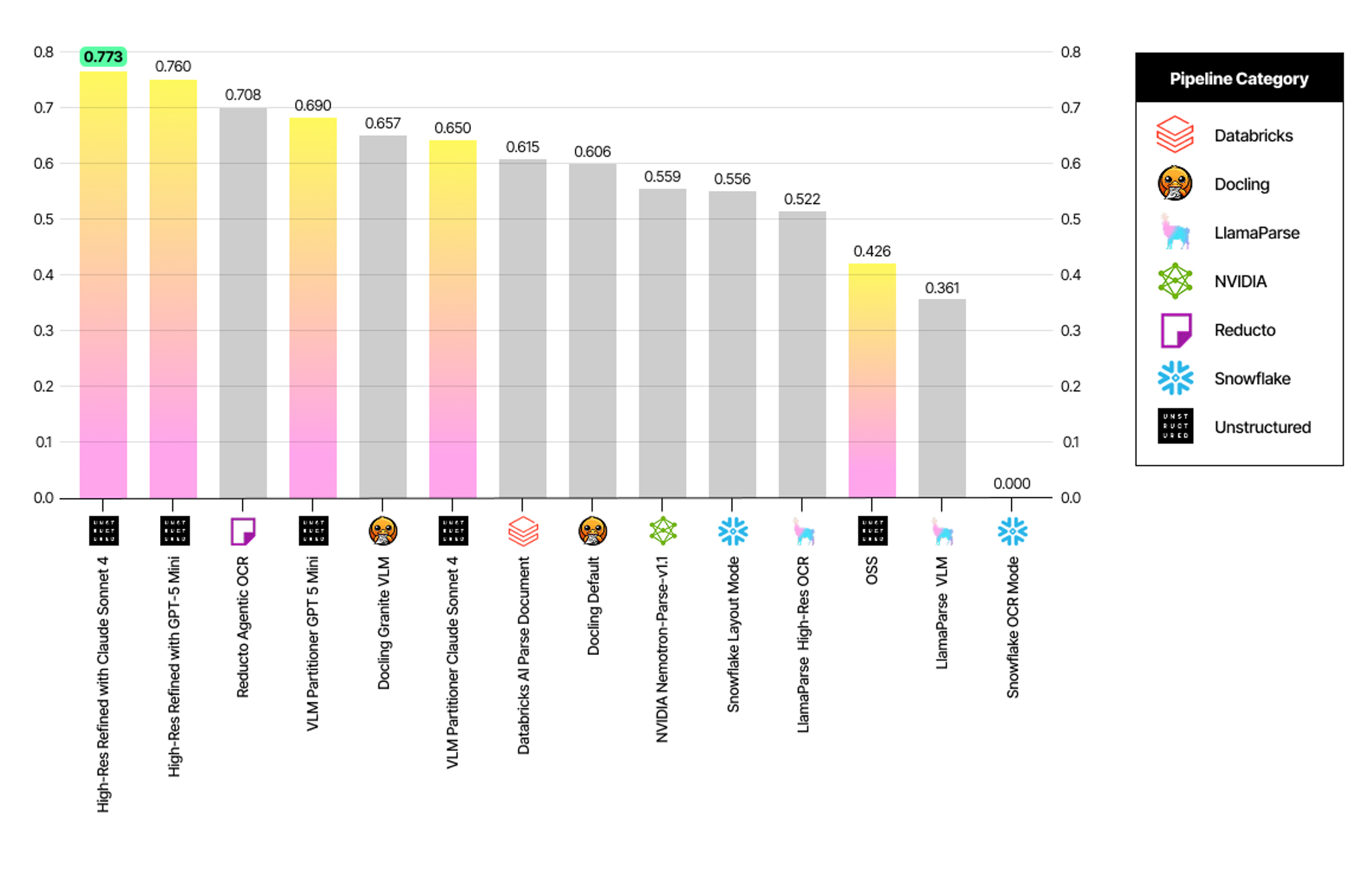
- Unstructured High-Res Refined with Claude Sonnet 4 pipeline leads with an accuracy of 0.773.
- The top three pipelines all come from Unstructured.
Cell Level Index Accuracy
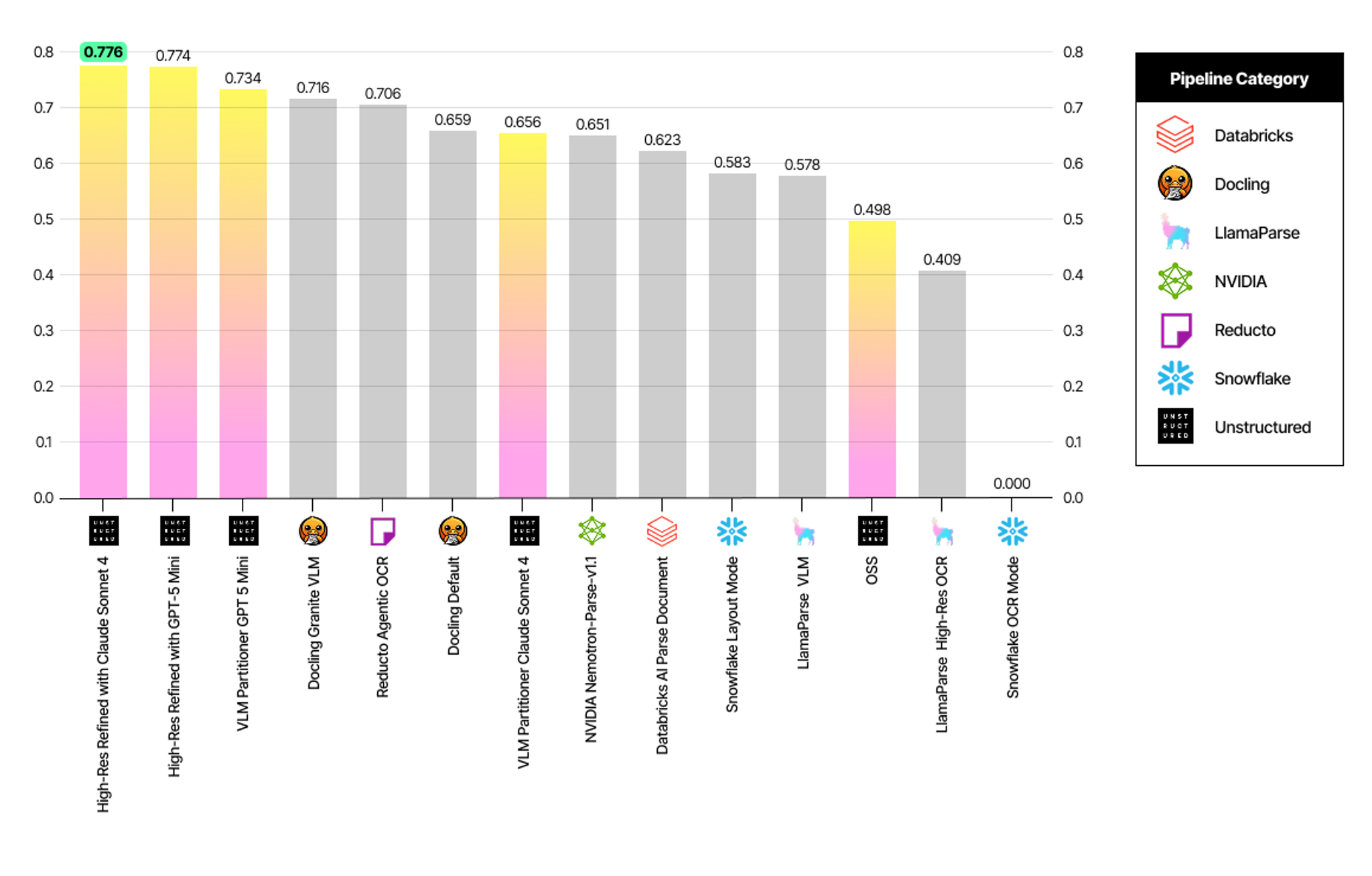
- Unstructured High-Res Refined with Claude Sonnet 4 also leads here with 0.776.
- Unstructured pipelines hold the top three positions in understanding the structural relationship of the text within tables.
Unstructured dominates table extraction. Unstructured leads on Cell Content Accuracy as well as Cell Level Index Accuracy, proving our system understands the structure of the table, not just the text.
Data That Matters
SCORE-Bench is designed to break brittle systems. We curated this dataset to ensure that high scores require genuine enterprise document understanding.
- Skew & Scan Artifacts: Systems must handle documents that have been physically scanned, photocopied, or photographed at angles.
- Dense Information: Financial tables often contain hundreds of cells spanning multiple pages; the benchmark penalizes systems that "give up" and output plain text instead of structured data.
- Semantic Ambiguity: Documents often use whitespace rather than lines to define columns. The benchmark tests if a system can distinguish between a two-column article and a list of key-value pairs.
You can explore the complete results and the data in the SCORE-Bench repository.
Try It Yourself
The best way to understand document parsing quality is to test systems on your own documents. Go ahead and try Unstructured today. Simply drag and drop a file from the Start page after login, and test the high-fidelity document transformation pipelines on your most challenging documents.


